识别炒作的 8 个指标:一份可重现的方法论
本文不只适用于 AI 投资,适用于所有技术叙事。每个指标都附带明确的打分规则,让方法论可复用、可验证、可质疑。
本文不只适用于 AI 投资,适用于所有技术叙事。每个指标都附带明确的打分规则,让方法论可复用、可验证、可质疑。
引子:为什么需要一个方法论?
每个时代都有”颠覆一切”的技术叙事:
- 1999 年:互联网将取代实体经济
- 2009 年:太阳能将取代化石燃料
- 2017 年:区块链将取代传统金融
- 2018 年:自动驾驶 5 年内普及
- 2021 年:元宇宙是下一代互联网
- 2024 年:AI 将创造 10 万亿美元价值
这些叙事中:
- 互联网部分实现了(用了 15 年,早期投资者大量被埋)
- 太阳能成本下降但市场份额仍小
- 区块链至今未实现核心命题(去中心化金融 < 1% 全球金融资产)
- 自动驾驶严重落后于承诺
- 元宇宙基本失败
- AI 处于早期,结果未知
问题不在于这些技术是真是假,而在于:
- 投资者很难在事中区分真趋势和炒作
- 即使是真趋势,时间表往往严重错误(互联网真兑现晚了 5-7 年,错位足以让所有早期投资者破产)
- 群体共识未必是真相——2000 年所有人都觉得”互联网是真的”,但具体公司的兑现度差异极大
所以我们需要一个结构化的判断框架:不是为了精确预测未来,而是为了避免最致命的错误。
这套方法论的设计原则
在介绍 8 个指标之前,需要明确几个原则:
1. 指标本身是主观的,但打分应该尽量客观
任何”识别炒作”的方法论都包含主观判断。但每个指标的打分应该有明确的标准,让不同的人对同一个对象打出相近的分数。
2. 不追求精确预测,追求避免错误
这套方法论不告诉你”X 公司股价 12 个月后涨多少”,但它能告诉你”X 公司是否值得严肃投资”。
3. 接受方法论的局限
8 个指标都是历史经验的总结,不能保证下一次泡沫会按同样规则展开。任何方法论都需要持续修正。
4. 区分”识别炒作”和”否定价值”
很多炒作的东西最终也成功了(比如互联网)。识别炒作不是为了判断”这个东西没价值”,而是为了判断”现在这个估值匹配哪个阶段的兑现”。炒作 ≠ 不会成功,炒作 = 时间错配。
关于 Gartner Hype Cycle 的背景
几乎所有重要技术都经历”膨胀峰 → 幻灭低谷 → 启蒙斜坡 → 生产力高原”的曲线,这是 Gartner 提出的经典模型:
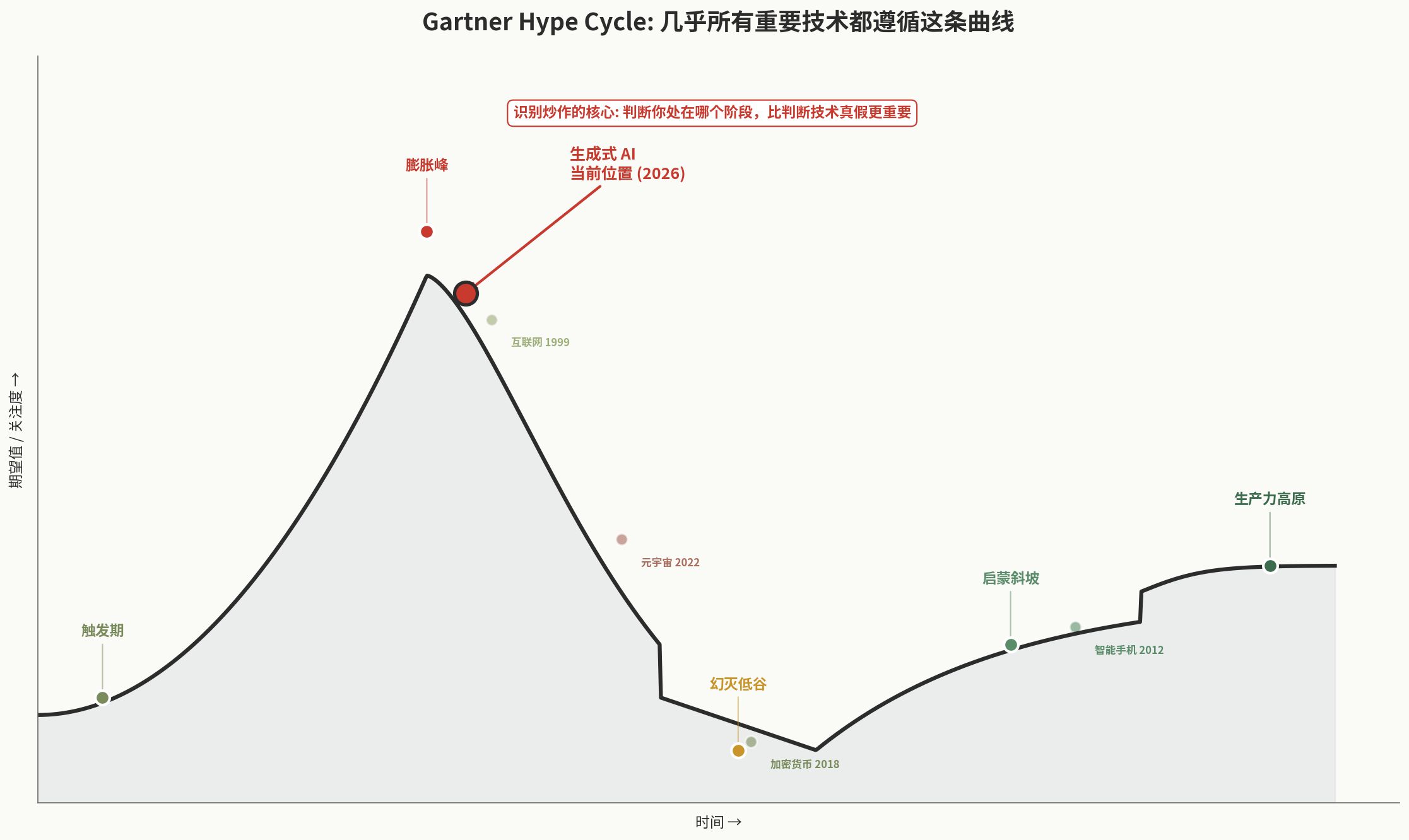
判断一个技术处于哪个阶段,比判断技术本身真假更重要。本文的 8 个指标,就是辅助这个判断的工具。
第一部分:8 个识别指标的设计
在逐一展开之前,先看一张总览——这 8 个指标的全貌:
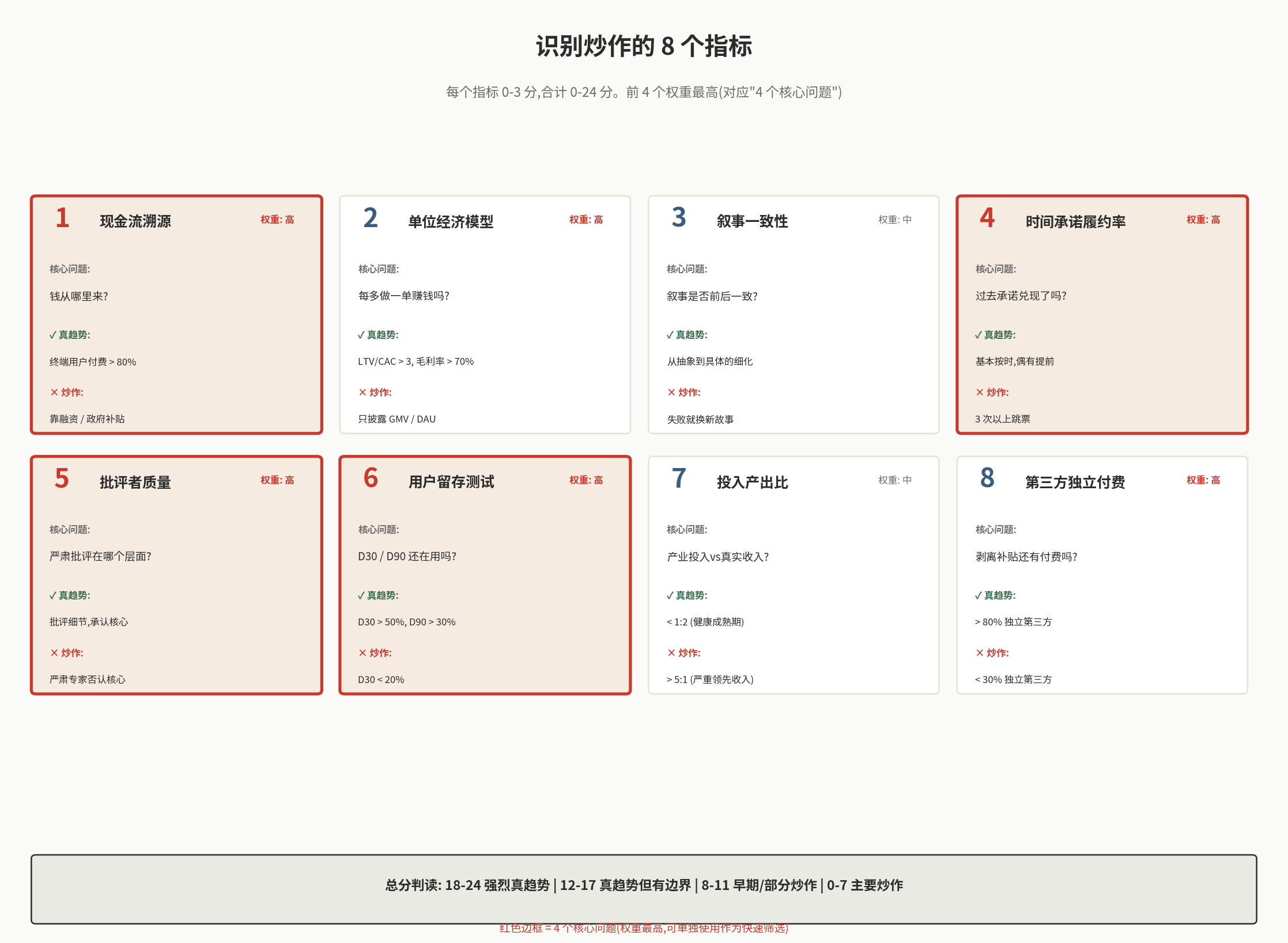
红色边框是权重最高的 5 个指标(对应后文的”4 个核心问题”,因为问题 1 同时对应指标 1 和 8)。如果时间紧张,重点理解这几个就够了。下面我们逐一展开。
指标 1 — 现金流溯源(权重最高)
核心问题:钱从哪里来?
判断逻辑:
- 真实价值的现金流路径是:终端用户 → 应用公司 → 平台公司 → 基础设施
- 炒作的现金流路径是:投资人 / 政府补贴 → 公司 → 资本开支
- 看一个产业,看终端付费起点是否真实存在
打分规则(0-3 分):
| 分值 | 标准 |
|---|---|
| 3 | 终端付费稳定 + 占总收入 > 80% + 毛利 > 50% |
| 2 | 终端付费稳定 + 占总收入 > 60% |
| 1 | 终端付费存在但占比 < 50%,主要靠融资 |
| 0 | 主要靠政府补贴 / 战略投资 / 关联交易 |
历史依据:
1999-2000 年互联网泡沫:B2B 电商网站融资数十亿美元,但 1999 年美国实际 B2B 电子商务交易额仅 1090 亿美元。估值严重领先于真实付费规模。融资停止后,公司迅速消失。
2021-2022 年元宇宙:Meta、Microsoft 投入数百亿美元,但消费者对元宇宙的真实付费意愿极低。没有终端付费,叙事崩溃。
应用举例:
- AI 编程(Claude Code):终端用户(开发者 + 企业)付费 > 95%,给 3 分
- 中国 AI 芯片:智算中心建设 / 央企采购 / 政府补贴占很大比例,难以完全剥离,给 1 分
- AI 改造制造业:项目制为主,很多是政府引导基金或国企试点,给 0-1 分
指标 2 — 单位经济模型
核心问题:每多做一单,赚钱还是亏钱?
判断逻辑:
- LTV/CAC > 3 是健康 SaaS 的标准
- 毛利率 > 70% 是软件级别
- 回收期 < 12 个月意味着资本效率高
- 当一个公司不愿展示这些数字,多半是因为单位经济不健康
打分规则(0-3 分):
| 分值 | 标准 |
|---|---|
| 3 | 公开数据中 LTV/CAC > 3 + 毛利率 > 70% + 公司主动披露 |
| 2 | 公开数据 LTV/CAC > 2 + 毛利率 > 50% |
| 1 | 用 GMV / DAU 等替代指标,回避单位经济讨论 |
| 0 | 单位经济为负(亏钱卖产品),靠融资烧钱 |
历史依据:
Pets.com(2000 年破产):每件商品销售亏损 25-30 美元,LTV/CAC < 0.5。靠融资烧钱掩盖。9 个月烧光 3 亿美元后破产。
Uber 早期(2014-2018):每单亏 6-8 美元,但持续融资。最终在 IPO 后才被迫展示真实单位经济,至今盈利能力有限。
警告信号:
公司的标准披露中如果只用以下指标,通常意味着不愿展示单位经济:
- GMV(成交总额)
- DAU / MAU(活跃用户数)
- 注册用户数
- 总下载量
- “用户增长率”(不是付费用户)
真正健康的公司喜欢披露:
- ARR(年化经常性收入)
- LTV/CAC
- 毛利率
- 净留存率(NDR > 110% 是 SaaS 健康标准)
指标 3 — 叙事一致性
核心问题:公司 / 行业的叙事在不同时期是否前后一致?
判断逻辑:
- 真趋势的叙事:从抽象到具体(互联网 → 电商 → B2C 零售 → Amazon Prime)
- 炒作的叙事:从具体到抽象,遇到反驳就换新故事
- 每次旧叙事失败都换新叙事是典型的炒作特征
打分规则(0-3 分):
| 分值 | 标准 |
|---|---|
| 3 | 5 年内核心叙事一致,每次更新都是细化 |
| 2 | 叙事有调整,但核心命题未变 |
| 1 | 主叙事每 2-3 年换一次,但底层逻辑相同 |
| 0 | 叙事不断变换,每次都是”全新机遇” |
历史依据:
下图直观对比互联网与区块链的叙事演化路径——一图胜千言:
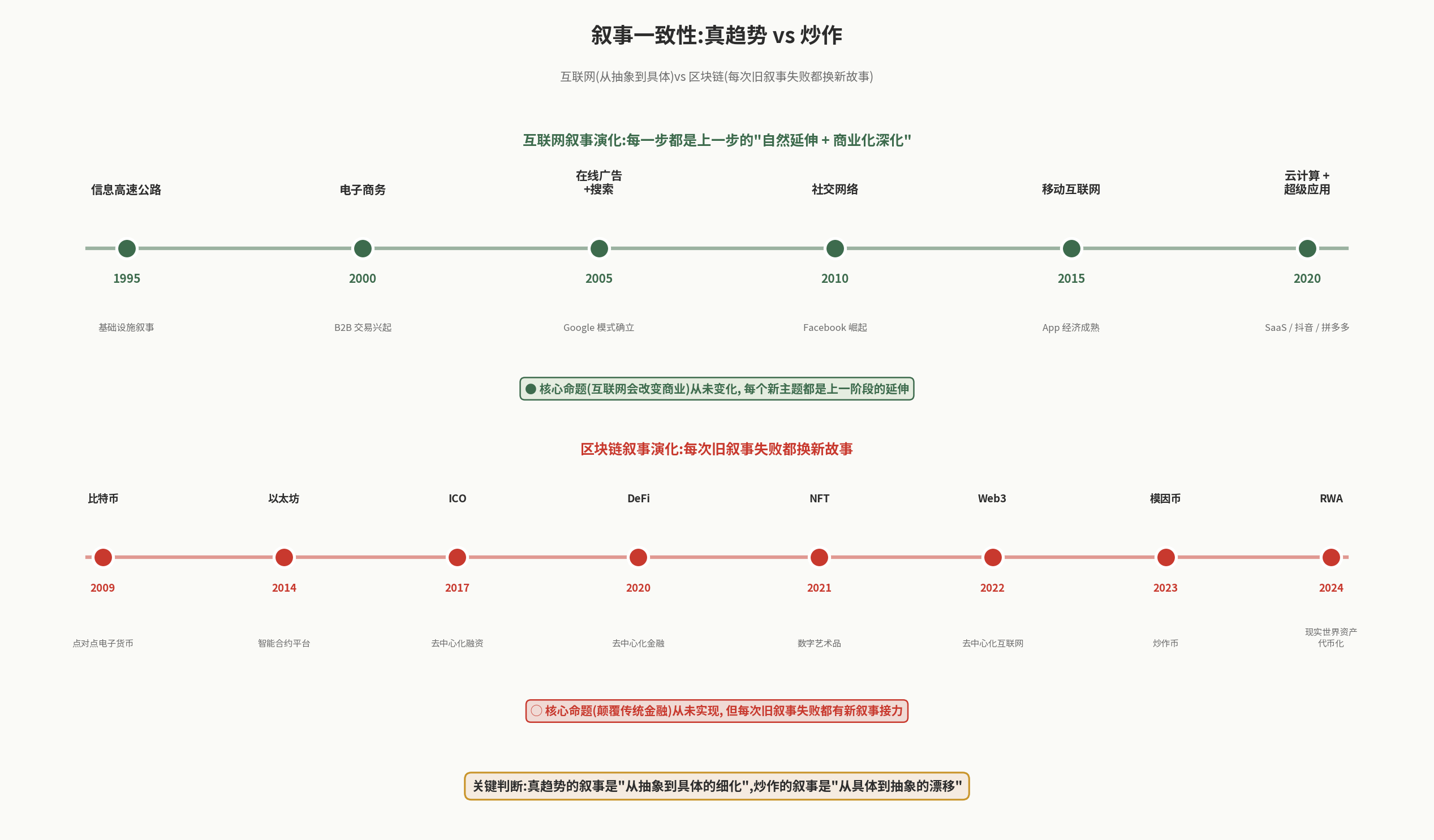
区块链 16 年叙事演化(典型炒作):
- 2009:比特币(点对点电子货币)
- 2014:以太坊(智能合约平台)
- 2017:ICO(去中心化融资)
- 2020:DeFi(去中心化金融)
- 2021:NFT(数字艺术品)
- 2022:Web3(去中心化互联网)
- 2023:模因币(炒作币)
- 2024:RWA(现实世界资产代币化)
核心命题(颠覆传统金融)从未实现,但每次旧叙事失败都有新叙事接力。
互联网叙事(典型真趋势):
- 1995:信息高速公路
- 2000:电子商务
- 2005:在线广告 + 搜索
- 2010:社交网络
- 2015:移动互联网
每一步都是上一步的自然延伸 + 商业化深化,而不是”全新概念”。
指标 4 — 时间承诺履约率
核心问题:行业 / 公司过去的承诺兑现了多少?
判断逻辑:
- 单次跳票:可接受(技术行业常见)
- 2 次跳票:警告(开始系统性怀疑)
- 3 次以上跳票:默认是炒作,直到证明否则
打分规则(0-3 分):
| 分值 | 标准 |
|---|---|
| 3 | 过去 3-5 年承诺基本按时兑现,偶有提前 |
| 2 | 单次跳票 6-12 个月,最终兑现 |
| 1 | 多次跳票,但核心方向兑现 |
| 0 | 持续跳票,承诺与现实严重背离 |
历史依据:
特斯拉自动驾驶(典型连续跳票):
- 2014 年 Musk:3 年内完全自动驾驶 ✗
- 2016 年:年底跨美国自动驾驶 ✗
- 2017 年:6 个月后 Robotaxi ✗
- 2019 年:明年 100 万辆 Robotaxi ✗
- 2020-2024 年:连续跳票
10 年内 7 次跳票,0 次按时兑现——按指标 4,自动驾驶得 0 分。
mRNA 疫苗(典型超预期兑现):
- 2010 年:Moderna 等公司承诺 mRNA 平台可行
- 2020 年 1 月:COVID 出现
- 2020 年 3 月:Moderna 完成首批疫苗设计
- 2020 年 12 月:FDA 批准
- 从概念到大规模部署不到 11 个月,远超传统疫苗 5-10 年的开发周期
mRNA 在指标 4 上得 3 分。
应用到 AI:
- AI 模型能力提升:GPT-3 → GPT-4 → GPT-5 → GPT-5.5 基本按 12-18 个月节奏发布,分数较高(2-3 分)
- AI Agent 兑现:2023 年说”今年是 Agent 年”,2024 年又说”今年是 Agent 年”,2025 年再说一遍——重复跳票,分数偏低(1 分)
- AGI:从 1956 年达特茅斯会议至今 70 年,时间表反复推迟,0-1 分
指标 5 — 批评者质量
核心问题:行业最严肃的批评者批评的是细节还是核心?
判断逻辑:
- 真趋势的批评者:批评细节、应用边界、推广速度,但承认核心价值
- 炒作的批评者:批评核心命题、否认基本逻辑
打分规则(0-3 分):
| 分值 | 标准 |
|---|---|
| 3 | 严肃批评者批评的都是细节,无人否认核心 |
| 2 | 多数批评是细节,少数严肃批评核心命题 |
| 1 | 严肃批评核心命题的人较多 |
| 0 | 多数严肃专家否认核心命题,只有从业者支持 |
历史依据:
对加密货币的批评:
经济学家 Krugman、Roubini、Munger 长期批评核心经济命题:
- “去中心化货币没有经济学基础”
- “比特币是没有底层资产的庞氏骗局”
- “区块链解决方案在寻找问题”
这些批评针对的是核心命题,且批评者都是诺贝尔奖级别 / 沃伦巴菲特合伙人级别。在指标 5 上加密货币得 0-1 分。
对互联网的批评:
1995-2000 年,几乎没有严肃经济学家否认互联网核心价值。批评集中在:
- “互联网公司估值过高”(细节)
- “.com 公司大部分会失败”(细节)
- “推广速度被高估”(细节)
但核心命题(互联网会改变商业)从未被严肃否认。互联网在指标 5 上得 3 分。
对 AI 的严肃批评:
LeCun(Meta 首席 AI 科学家)、Marcus(NYU 教授)、Bender(Stanford)等批评的是实现路径:
- “Transformer 架构有根本性局限”
- “Scaling Laws 会遇到天花板”
- “当前 LLM 不是通向 AGI 的正确路径”
但几乎没有严肃专家否认 AI 创造价值的能力。AI 在指标 5 上得 2-3 分。
这是 AI 与加密货币最根本的差异——AI 的核心命题被广泛接受,加密货币的核心命题被广泛质疑。
指标 6 — 用户留存测试
核心问题:用户用过之后还来吗?
判断逻辑:
- 30 天留存(D30)和 90 天留存(D90)是产品价值的最严格证据
- 如果产品对用户真有价值,他们会持续使用
打分规则(0-3 分):
| 分值 | D30 留存 | D90 留存 |
|---|---|---|
| 3 | > 50% | > 30% |
| 2 | 30-50% | 15-30% |
| 1 | 15-30% | 5-15% |
| 0 | < 15% | < 5% |
历史依据:
Clubhouse(典型炒作):
- 巅峰时期 1000 万 MAU(2021 年初)
- 6 个月内 D30 跌至 < 15%
- 2022 年裁员转型,公司价值大幅缩水
TikTok / 抖音(典型真趋势):
- 持续 5+ 年 D30 > 60%
- D90 > 40%
- 至今仍是用户时间消耗最大的应用之一
应用到 AI 产品:
- ChatGPT:D30 留存约 60%(OpenAI 公开披露),3 分
- Claude:D30 留存约 50%,3 分
- GitHub Copilot 付费用户:年留存 > 80%,3 分
- 大量 AI 工具创业公司:D30 < 25%,0-1 分(信号:活跃用户数远小于注册数)
指标 7 — 投入产出比
核心问题:产业整体投入与真实收入的比例?
判断逻辑:
- 过去成熟产业的健康比例约 1:3 到 1:5(投入:收入)
- 高速成长期可以达到 1:1(投入大但收入快速接力)
- 投入大于收入意味着未来收入需要快速兑现才能消化
打分规则(0-3 分):
| 分值 | 比例(投入:收入) |
|---|---|
| 3 | < 1:2(健康成熟期) |
| 2 | 1:1 至 1:2(高速成长期) |
| 1 | 2:1 至 5:1(高投入,未兑现) |
| 0 | > 5:1(投入严重领先收入) |
历史依据(与第 1 篇 4.2 节呼应):
| 时期 | 比例 | 后续 |
|---|---|---|
| 1999-2000 电信泡沫 | 6:1 | 崩溃 |
| 2005-2010 互联网成熟期 | 1:4 | 健康 |
| 2012-2020 移动互联网 | 1:3 | 健康 |
| 2025 AI | 6.9:1 | ? |
| 2026 AI | 10.5:1 | ? |
下图直观对比这些历史时期:
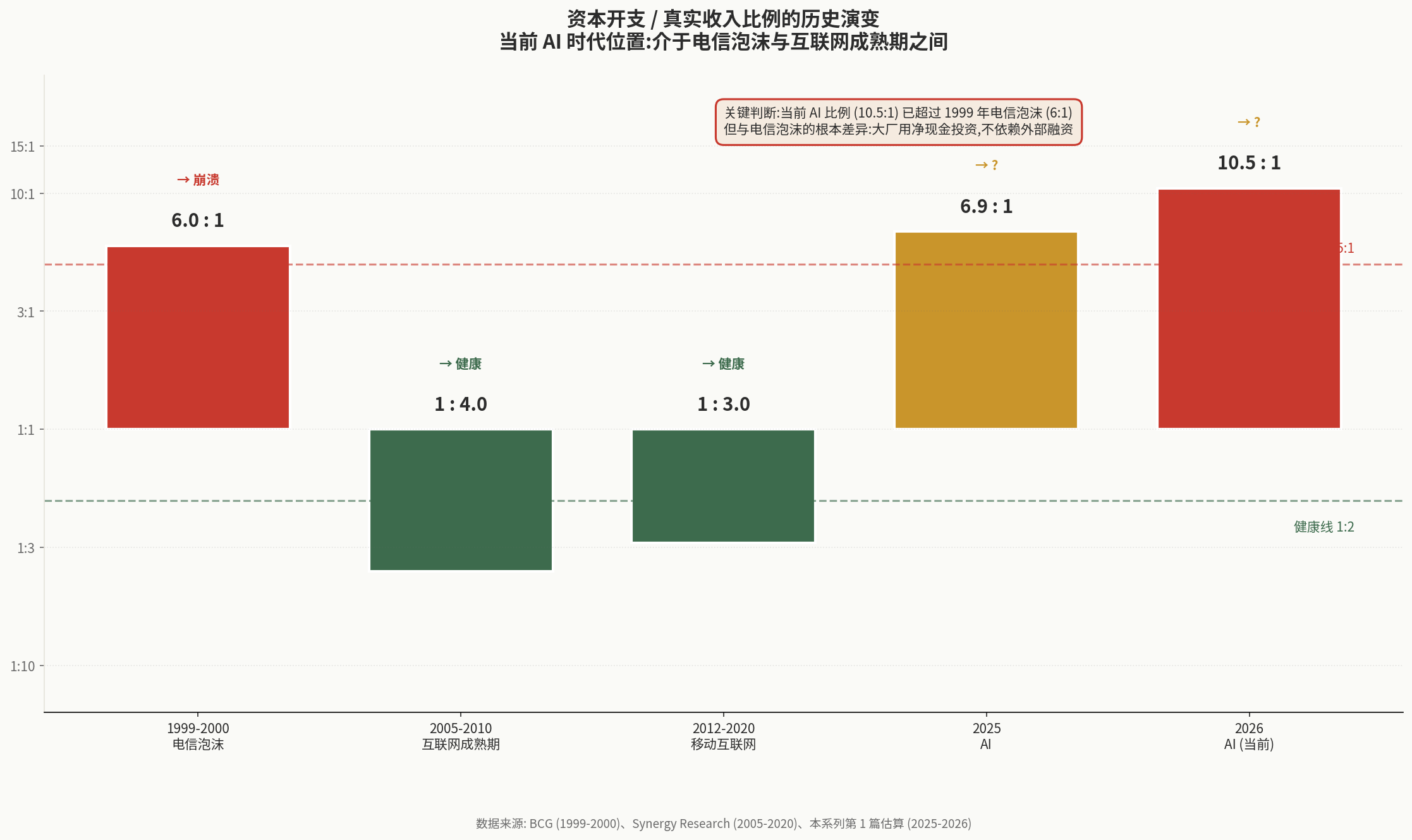
AI 当前在指标 7 上得 0 分,且趋势在恶化。这是当前 AI 投资最大的系统性风险。
但要注意(这是与第 1 篇 4.3 节呼应的反思):
- 投入方的财务健康度(大厂净现金状态)显著优于 1999 年电信公司
- 终端付费现金流真实存在
- 这意味着即使比例恶化,也未必会像 2001 年那样系统性崩溃
指标 7 给出 0 分不等于”必崩”,而是说”风险信号已经非常强”。
指标 8 — 第三方独立付费意愿(最严苛)
核心问题:完全独立、没有补贴、没有关联方的第三方愿意付费吗?
判断逻辑:
- 政府补贴、关联方采购、战略投资构成的”伪付费”会扭曲单位经济
- 真正的市场验证是独立第三方愿意拿出真金白银
打分规则(0-3 分):
| 分值 | 标准 |
|---|---|
| 3 | > 80% 收入来自独立第三方付费 |
| 2 | > 60% 收入来自独立第三方 |
| 1 | 30-60% 来自独立第三方,其余靠补贴/关联 |
| 0 | < 30% 独立付费,主要靠政策驱动 |
历史依据:
3D 打印(2013-2014 炒作):
- 90% 工业 3D 打印机销售给研究机构、大学、政府实验室
- 真正用于工业生产的 < 10%
- 股价暴涨 5-10 倍后跌掉 80-90%
- 在指标 8 上得 0-1 分
应用到中国 AI 芯片产业链:
剔除以下”伪付费”后看真实第三方付费:
- 政府补贴(智算中心建设、AI 产业引导基金)
- 关联方采购(华为系采购海思 / 海光、阿里系采购平头哥)
- 央企采购(三大运营商、国家电网等政策性需求)
- 高校 / 研究院采购
剔除后估算:国产 AI 芯片公司真正第三方付费 < 30%。在指标 8 上得 0-1 分。
应用到美国 AI 大厂:
- NVIDIA、TSMC、Microsoft、Google:客户极度多元,独立付费占绝对多数。3 分。
- OpenAI:消费者订阅 + 企业付费,几乎全部独立。3 分。
第二部分:综合评分卡的应用
2.1 评分汇总规则
每个指标 0-3 分,8 个指标合计 0-24 分。
| 总分 | 等级 | 含义 |
|---|---|---|
| 18-24 | 强烈真趋势 | 已被现金流和单位经济严格验证 |
| 12-17 | 真趋势但有边界 | 真兑现存在,但天花板或时间不确定 |
| 8-11 | 早期 / 部分炒作 | 有真兑现痕迹,但叙事大于现金流 |
| 0-7 | 主要炒作 | 大部分价值依赖叙事而非现金流 |
2.2 重要警告
这套评分有几个不能避免的局限:
1. 主观性:每个指标的打分都需要主观判断。同一个对象,两个分析师可能打出 3 分差距。
2. 历史归纳:基于过去 30 年的技术周期。如果 AI 真的是工业革命级别的变革,历史规律可能不适用。
3. 时点依赖:今天打 12 分的领域,可能 6 个月后变成 18 分(兑现加速)或 8 分(叙事破灭)。评分需要持续更新。
4. 指标权重:本方法论假设 8 个指标等权重,但实际上指标 1(现金流溯源)和指标 8(第三方付费)应该更高权重。读者可以自己调整权重。
2.3 实战示例:4 个领域的评分
下图是 4 个领域的 8 维度评分对比可视化(详细论证见后):
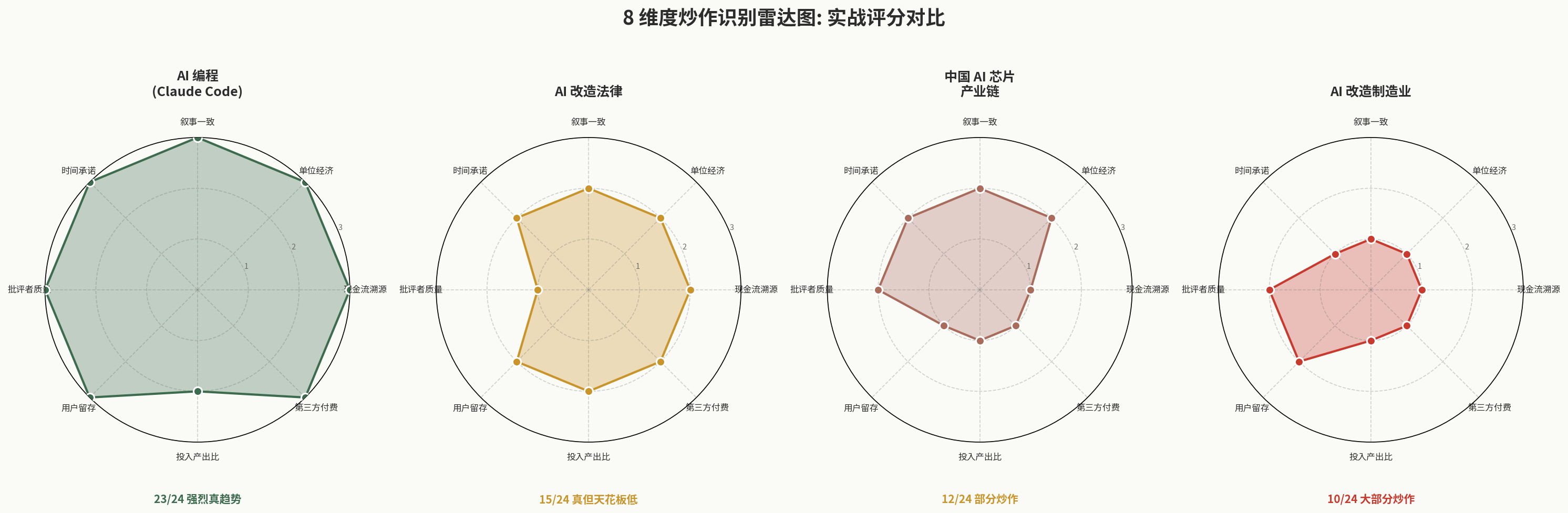
可以直观看出:AI 编程接近满分(23/24),AI 制造业大部分维度都偏低(10/24)。下面给出每个领域的详细论证。
示例 1:AI 编程(Claude Code、Cursor 等)
| 指标 | 评分 | 论证 |
|---|---|---|
| 1 现金流溯源 | 3 | 95%+ 来自开发者和企业付费 |
| 2 单位经济 | 3 | LTV/CAC > 5(开发者付费意愿强);毛利 > 75% |
| 3 叙事一致 | 3 | 从 “AI 辅助编程” 到 “AI Agent 编程” 是细化,不是漂移 |
| 4 时间承诺 | 3 | 模型能力提升按预期兑现,工具迭代快 |
| 5 批评者质量 | 3 | 几乎无人否认 AI 编程价值,批评在边界(取代谁、不取代谁) |
| 6 用户留存 | 3 | GitHub Copilot 年留存 > 80% |
| 7 投入产出比 | 2 | 整体行业投入产出比一般,但具体到 AI 编程子领域较好 |
| 8 第三方付费 | 3 | 客户极度多元,无关联交易 |
| 合计 | 23/24 | 强烈真趋势 |
示例 2:AI 改造法律
| 指标 | 评分 | 论证 |
|---|---|---|
| 1 现金流溯源 | 2 | 80%+ 来自律所付费 |
| 2 单位经济 | 2 | 毛利率较好(60-70%)但 LTV/CAC 数据不公开 |
| 3 叙事一致 | 2 | ”AI 替代律师” → “AI 辅助律师” 是合理收敛 |
| 4 时间承诺 | 2 | 推进略慢于预期但未严重跳票 |
| 5 批评者质量 | 1 | 法律专业人士对核心命题(AI 能否做法律判断)有真实质疑 |
| 6 用户留存 | 2 | 律所一旦采购,留存高,但渗透率慢 |
| 7 投入产出比 | 2 | 投入相对克制,产出按节奏来 |
| 8 第三方付费 | 2 | 主要是商业律所,付费独立性强 |
| 合计 | 15/24 | 真趋势但天花板低 |
示例 3:中国 AI 芯片产业链
| 指标 | 评分 | 论证 |
|---|---|---|
| 1 现金流溯源 | 1 | 大量来自智算中心 / 央企采购,独立终端付费占比难以剥离 |
| 2 单位经济 | 2 | 毛利率较好但 LTV/CAC 不可知 |
| 3 叙事一致 | 2 | ”国产替代” 叙事 5 年一致,但具体路径反复变化 |
| 4 时间承诺 | 2 | 性能追赶承诺基本按节奏,但生态承诺多次跳票 |
| 5 批评者质量 | 2 | 严肃质疑集中在 “生态” 而非 “硬件能力” |
| 6 用户留存 | 1 | 政策驱动采购,真实留存数据不公开 |
| 7 投入产出比 | 1 | 国家投入大,市场化收入不成比例 |
| 8 第三方付费 | 1 | 真正独立第三方付费占比可能 < 30% |
| 合计 | 12/24 | 早期 / 部分炒作 / 政策驱动 |
示例 4:AI 改造制造业
| 指标 | 评分 | 论证 |
|---|---|---|
| 1 现金流溯源 | 1 | 大量来自政府引导基金 / 国企试点 |
| 2 单位经济 | 1 | 项目制为主,单位经济概念都难定义 |
| 3 叙事一致 | 1 | ”工业互联网” → “数字化转型” → “AI 工厂” 反复变换 |
| 4 时间承诺 | 1 | ”灯塔工厂” 等承诺多次跳票 |
| 5 批评者质量 | 2 | 严肃工业人士对核心命题有真实质疑 |
| 6 用户留存 | 2 | 单个项目落地后留存高,但渗透极慢 |
| 7 投入产出比 | 1 | 政府投入大,市场化产出不成比例 |
| 8 第三方付费 | 1 | 多为政策驱动 |
| 合计 | 10/24 | 大部分炒作 |
2.4 这些评分意味着什么
重要提醒:评分不直接等于”应该买/卖”。
- AI 编程 23/24 → 强趋势,但 Claude Code 没有上市,相关投资标的(Microsoft 持有 GitHub Copilot、Anthropic 即将 IPO)需要单独估值
- AI 改造法律 15/24 → 真趋势但天花板低,意味着相关公司(Harvey 等)的估值不应该按”千亿美金市场”给
- 中国 AI 芯片 12/24 → 部分炒作,意味着估值应该谨慎,当前 PE 348x(寒武纪)/ 260x(海光)已经反映了”完全真趋势”的预期,安全边际很薄
- AI 改造制造业 10/24 → 大部分炒作,相关概念股不应该在严肃 portfolio 里
第三部分:4 个核心问题(精简版)
如果觉得 8 个指标太复杂,可以浓缩成 4 个核心问题。这 4 个问题对应了 8 个指标中权重最高的 4 个:
问题 1:把所有融资和补贴剥掉,公司能活吗?
对应指标 1(现金流溯源)+ 指标 8(第三方付费)
判断方法:
- 看公司收入构成中”独立第三方付费”占比
- 假设融资环境收紧、政策补贴消失,公司还能继续运营吗?
- 如果答案是”不能”,那么当前估值不可持续
问题 2:这个行业 3 年前的承诺兑现了多少?
对应指标 4(时间承诺)
判断方法:
- 列出该行业 / 公司 3 年前的公开承诺(产品发布时间表、市场目标、技术里程碑)
- 检查实际兑现情况
- 兑现率 > 60% 通常是真趋势的特征
- 兑现率 < 30% 应该高度警惕
问题 3:行业最权威的批评者批评的是细节还是核心命题?
对应指标 5(批评者质量)
判断方法:
- 找到该行业 / 公司最权威的 3-5 位严肃批评者
- 阅读他们近期的批评文章 / 言论
- 判断批评的层级(核心命题 / 路径 / 速度 / 边界)
- 如果严肃批评者否认核心命题,应该认真对待
问题 4:用户用过之后,30 天和 90 天还在用吗?
对应指标 6(用户留存)
判断方法:
- 寻找该产品的 D30 / D90 留存数据
- 如果不公开,看用户活跃数据 / 月度续费率
- 留存差的产品没有真实价值
综合判断规则
4 个问题中 3 个以上指向”炒作” = 强烈警告信号
例如:
- 公司主要靠融资 + 3 年前承诺基本没兑现 + 严肃批评者否认核心 = 几乎肯定是炒作
- 即使第 4 个问题(用户留存)数据好,前面 3 个的负面信号已经足够说明问题
第四部分:方法论的局限
为了诚实,必须列出本方法论的局限:
4.1 历史归纳的局限
这套指标基于过去 30 年的技术周期归纳。如果出现真正的范式转移(如工业革命级变革),历史规律可能失效。
反例思考:1900 年的人用”过去 100 年的经验”判断电力,会得出什么结论?很可能严重低估电力的长期价值。
应对:方法论是”概率工具”而非”绝对真理”。在大趋势上保持开放,但在具体投资上应用方法论防止严重错误。
4.2 时间维度的局限
这套指标判断的是”当前时点的健康度”,无法判断未来的演化。
例如:2010 年的 SpaceX 在指标 7(投入产出比)上得 0 分(投入巨大,收入很少),但 15 年后成为最成功的商业航天公司。
应对:评分应该作为”风险信号”使用,而不是”否决标准”。低分领域需要更高的潜在回报来补偿风险。
4.3 群体智慧的悖论
如果所有人都用这套方法论,那么市场会迅速 price in 高分项目,导致估值过高,反而降低投资回报。
应对:方法论的价值不在于发现”高分公司”(市场也能发现),而在于避免重仓”低分公司”——即使该公司的故事再动听。
4.4 主观性
每个指标的打分都需要分析师的主观判断。两个使用同一方法论的人可能给出不同评分。
应对:评分应该公开论证(而非只给数字),让其他人能质疑、验证、修正。本文实战示例的论证就是这种公开。
第五部分:方法论与具体决策的关系
这套方法论不直接告诉你买什么、不买什么。它告诉你:
- 哪些领域当前估值的”叙事 vs 现金流”不平衡
- 哪些公司主要靠故事支撑估值
- 哪些风险信号已经亮起
具体决策还需要考虑:
- 你的风险承受能力
- 你对每种情景的概率判断
- 你的资金占用周期
- 你能持续追踪信息的能力
例如:
- 评分 23/24 的 AI 编程是真趋势,但相关上市标的可能估值已经反映,超额收益空间未必大
- 评分 12/24 的中国 AI 芯片是”早期 + 部分炒作”,但如果你能买在严重低估时(比如未来某次系统性回调),仍然可能有大幅收益
评分 ≠ 投资建议。它是输入,不是输出。
结语:这套方法论真正的用处
本文不是要你”机械地给每只股票打分”。它的真正用处是:
- 当你听到一个动人的技术故事时,用 4 个核心问题筛一遍,避免最致命的错误
- 当你和朋友 / 卖方分析师讨论时,用 8 个指标作为讨论框架,让对话更结构化
- 当你做配置决策时,用评分校准每个标的的”潜在风险”,调整仓位
- 当你检视自己的判断时,用评分作为”反思镜”,避免过度乐观或过度悲观
最重要的——这套方法论本身也应该被持续质疑和修正。
如果未来 5 年某个评分 8/24 的领域大爆发,那说明方法论需要修正。如果某个评分 22/24 的领域突然崩溃,也是修正的契机。
真正的方法论不是”正确答案”,而是”可被改进的提问方式”。
系列其他文章
本文不构成投资建议。所有评分均为基于公开数据的方法论演示。读者应根据自身判断使用。
评论
登录后发表评论
还没有评论,来留下第一条吧